Le processus de reconnaissance vocale informatique s’est d’ailleurs grandement amélioré avec l’apparition de l’intelligence artificielle, par laquelle on « expose » l’ordinateur à une grande variété de signaux de parole, ce qui améliore sa capacité à prédire ce qui a été produit.
PARTIE C : Les réseaux impliqués dans la perception de la parole
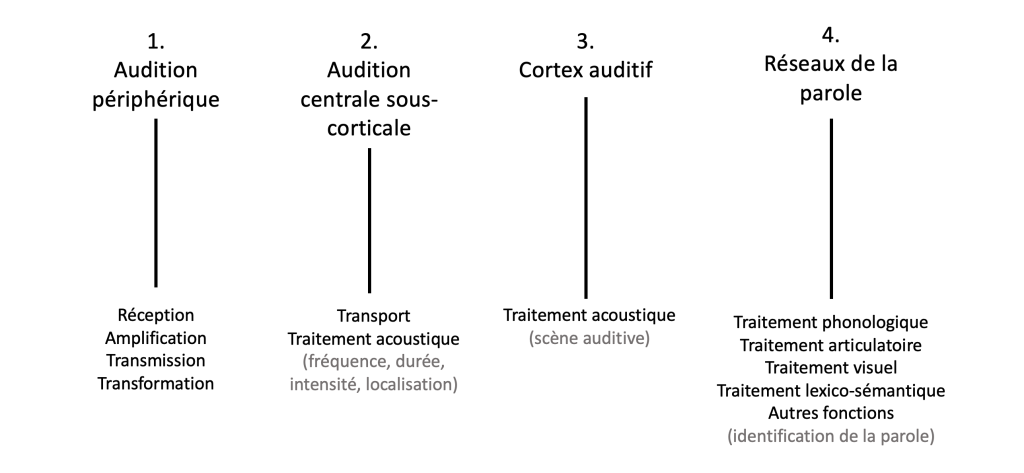
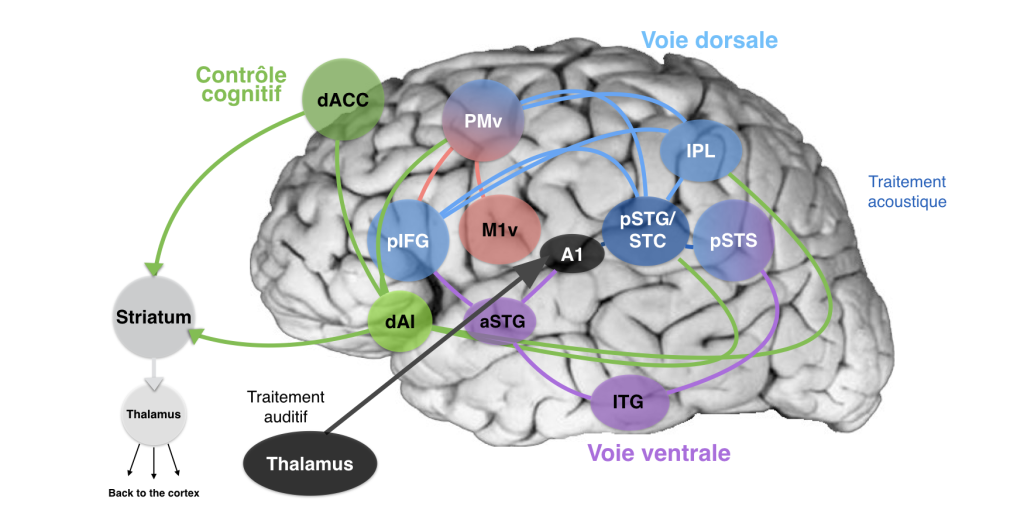
Les données recueillies grâce aux techniques de neuroimagerie et de neurostimulation au cours des quarante dernières années ont contribué à une meilleure compréhension des mécanismes neurobiologiques qui sous-tendent la perception de la parole. Comme mentionné précédemment, l’interprétation du signal de parole est difficile et nécessite la participation d’une multitude de systèmes différents qui interagissent (figure 4 ci-dessous).
Le cortex temporal supérieur (incluant le gyrus temporal supérieur et le sulcus temporal supérieur) est classiquement identifié comme étant une région au cœur de la perception de la parole. C’est notamment dans la région postérieure de ce cortex que se trouveraient les représentations abstraites auditives (dites « phonologiques ») de la parole.
Comme discuté ci-dessus, plusieurs niveaux de représentations contribuent au traitement de la parole. En effet, les régions associées au traitement visuel (lobe occipital), multimodal (lobule pariétal inférieur ou IPL) et articulatoire (cortex prémoteur ou PMv, cortex moteur primaire ou M1) contribuent aussi à l’identification des sons du langage à travers la voie dorsale de la parole (Figure 4).
Les régions associées au traitement sémantique (l’accès à la signification, au sens des mots, des discours, des concepts) participent également à la perception de la parole (pôle temporal, gyrus temporal moyen et gyrus temporal inférieur ou ITG) à travers la voie ventrale. Les représentations sémantiques permettent à notre cerveau de prédire les mots qui ont été dits en fonction du contexte et de notre lexique mental. Le gyrus inférieur frontal (IFG) est une autre région-clé du traitement de la parole et du langage, étant notamment impliquée dans le traitement phonologique (partie postérieure) et l’accès lexical (partie antérieure).
Finalement, des régions impliquées dans les fonctions cognitives et exécutives (p. ex. la mémoire verbale à court terme, pour mémoriser les sons entendus, l’attention ; en vert sur la figure 4) sont sollicitées durant le traitement de la parole, incluant le gyrus cingulaire, le cortex insulaire, le striatum, et le thalamus.



{kind=link}