Voice recognition systems have greatly improved with the use of artificial intelligence. These systems are now trained through exposition to large corpora of speech, which improves their ability to decipher what was produced.
PART C: Networks involved in speech perception
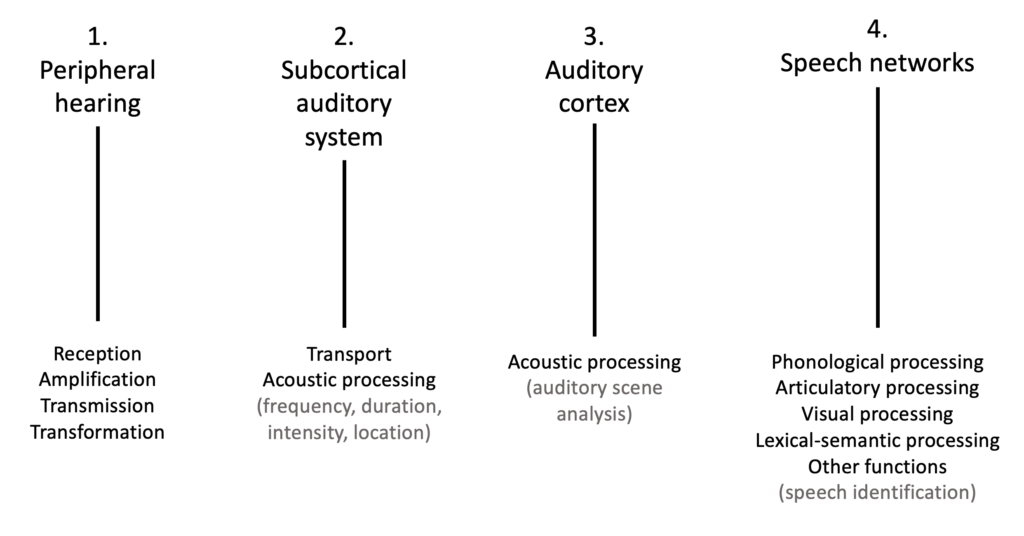
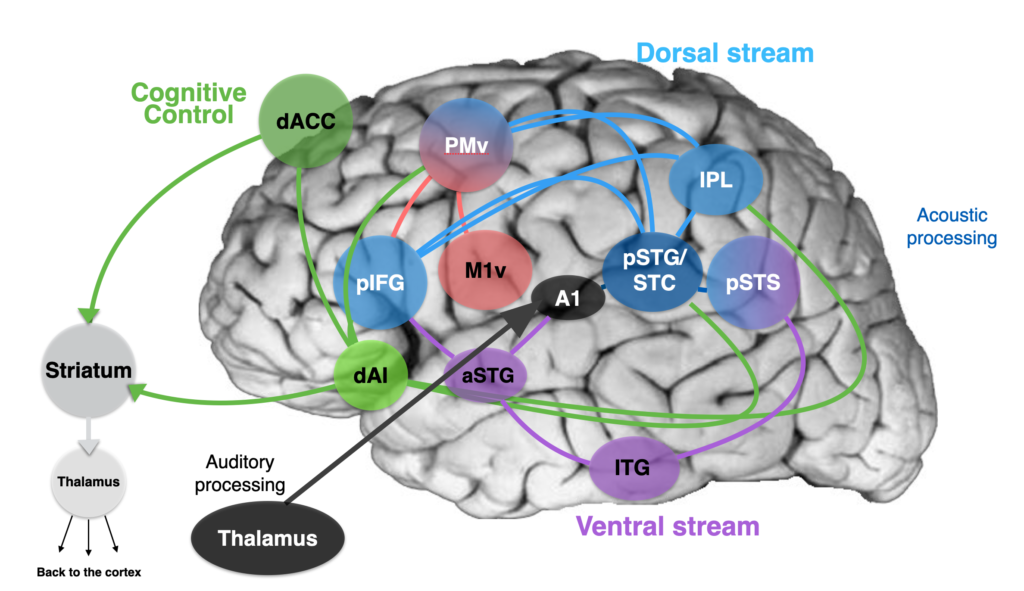
In the past 40 years or so, brain imaging and brain stimulation techniques have contributed to a better understanding of the neurobiological mechanisms underlying speech perception. As mentioned earlier, the interpretation of the speech signal is difficult and requires the participation of a variety of interacting systems (Figure 4 below).
The superior temporal cortex (including the superior temporal gyrus and the superior temporal sulcus) is classically identified as a key region for speech perception. The auditory abstract representations of speech (known as “phonological” representations) are believed to be stored in the posterior region of this cortex.
As discussed above, several levels of representations are engaged during speech processing. Indeed, the regions associated with visual processing (occipital lobe), multimodal processing (inferior parietal lobule or IPL) and articulatory processing (premotor cortex or PMv, primary motor cortex or M1) also contribute to the identification of speech sounds through the dorsal speech stream (Figure 4).
The regions associated with semantic processing (access to the meaning of words, sentences, discourse) also participate in the perception of speech (temporal pole, middle temporal gyrus and inferior temporal gyrus or ITG) through the ventral speech stream. Semantic representations allow our brain to decipher words that have been spoken based on the context and on our mental lexicon (i.e., our mental “dictionary”). The inferior frontal gyrus (IFG) is another key region for speech and language processing. It is involved in phonological processing and phonological memory (posterior part) and lexical access (anterior part).
Finally, regions involved in cognitive and executive functions (e.g., short-term verbal memory, memorization of heard sounds, or attention; shown in green in Figure 4) are also engaged during speech processing, including the cingulate gyrus, insular cortex, striatum, and thalamus.




{kind=link}