The cocktail party explained

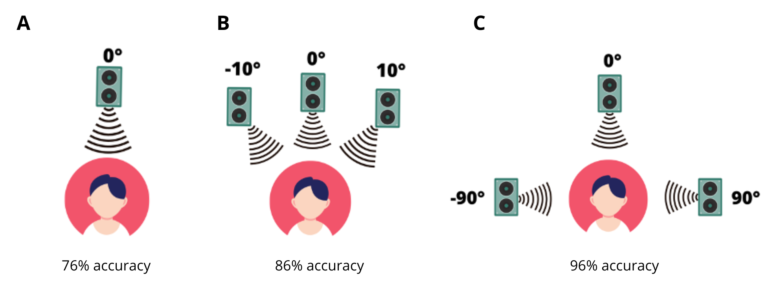
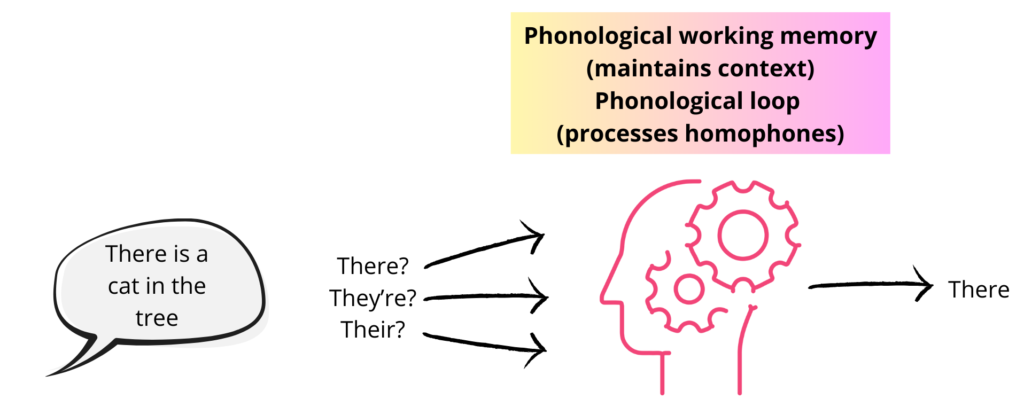
Transition Probability
When talking to a friend in a busy social event, the background noise will degrade the speech stream. This degradation of the speech stream can cause us to struggle to understand individual words. So how are we able to break up this stream to understand what our friend is saying? Our brain uses a type of information that is referred to as “transition probabilities”. That is, we calculate how likely one syllable is to follow or precede another. Each language in the World possesses its own set of statistics. A low probability usually indicates the end of a word; this information can be used to decode the speech stream.
For example, the probability that the phoneme “q” is followed by a “u” is extremely high in English, so it can be assumed they are part of the same word. Whereas the probability that the phoneme “d” is followed by the phoneme “f” within the same word is very low in English, therefore it can be assumed that this is the start of a new word (Dal Ben, Souza & Hay, 2021). Findings from our lab suggest that the left anterior and middle planum temporale areas of the brain may be recruited for the predictive aspects of the process (Tremblay, Baroni & Hasson, 2012). Using transition probability can help us break down the speech stream and can help us restore the missing signal caused by the loud environment.
Conclusion
The cocktail party effect occurs thanks to numerous different processes acting simultaneously. More and more work is being done to explore the intricate details of these processes as well as factors that can affect these processes, such as age, hearing and vision, language background and many others. In our lab, we investigate how age and musical experience affect the perception of speech in noise and methods to reduce this effect such as brain stimulation.




{kind=link}