La base de données de mots et de lemmes
En 2018, deux nouvelles bases de données, celles des mots et des lemmes, ont été ajoutées au projet SyllabO+.
La construction de ces deux outils a impliqué deux processus essentiels : la tokenisation et la lemmatisation. La tokenisation est un processus consistant à diviser un texte en unités plus petites, appelées « tokens », généralement des mots. Chaque mot du corpus a ensuite été intégré dans une base de données, accompagné d’informations grammaticales telles que son genre (masculin vs. féminin grammatical), son nombre (singulier vs pluriel) et ses marques de conjugaison. Dans un deuxième temps, la lemmatisation a permis de convertir ces mots en leur forme canonique, ou lemme, telle qu’on la retrouverait dans un dictionnaire. Par exemple, le lemme du verbe « courent » est « courir ».
La base de données des morphèmes
L’analyse morphologique a été réalisée à partir de la base de données des mots uniques mentionnée précédemment. Chaque mot a été segmenté en morphèmes puis codé dans la base de données. Un morphème est la plus petite unité porteuse de sens dans une langue. Par exemple, le mot incompréhensible comprend trois morphèmes : le préfixe in- (signifiant « non »), la racine compréhens- (issue du verbe comprendre) et le suffixe -ible (indiquant « qui peut être »). On distingue les morphèmes flexionnels des morphèmes dérivationnels. Les morphèmes flexionnels modifient un mot pour en indiquer le genre, le nombre ou le temps (comme les terminaisons verbales), tandis que les morphèmes dérivationnels servent à créer de nouveaux mots à partir de mots existants.
Pour élaborer la base de données des morphèmes, tous les mots du corpus ont été analysés au niveau de leur structure morphologique. Étant donné qu’ils ne sont pas segmentables en morphèmes, les mots monosyllabiques, tels que « pain », « chat » et les mots grammaticaux, tels que les déterminants, les pronoms, les prépositions ou les adverbes, ont été exclus de l’analyse. Chaque mot a été classé selon qu’il soit dérivé ou non, et les racines ainsi que les affixes ont été identifiés et segmentés afin de fournir une description précise de leur composition interne.
L’étude de la transparence sémantique
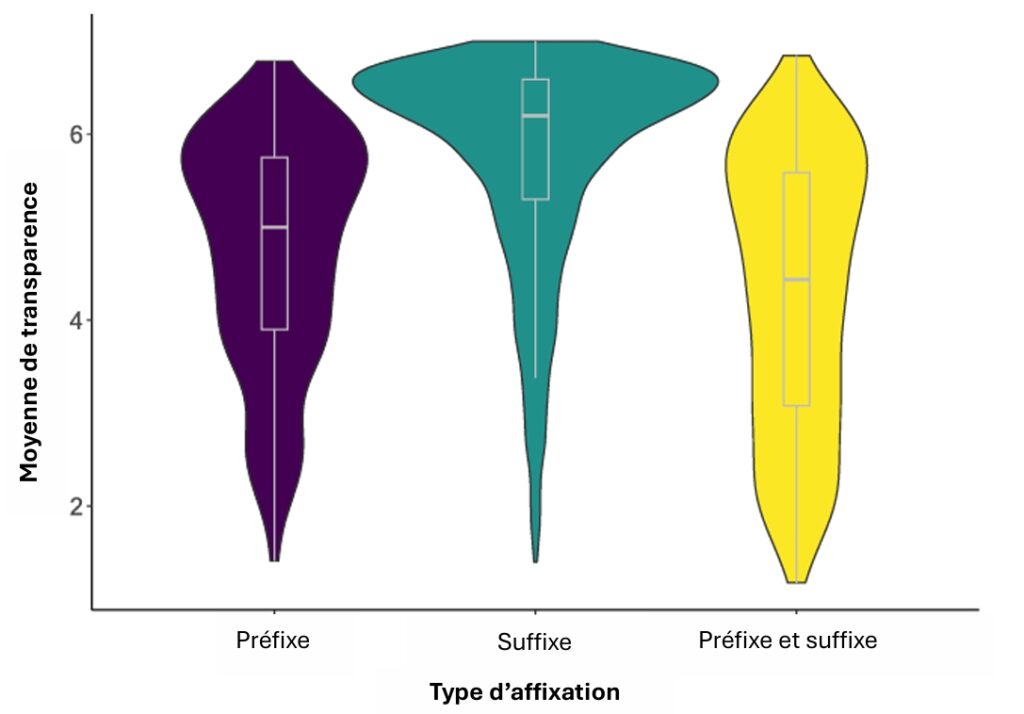
En plus de présenter la création de ces trois nouvelles bases de données, notre article visait également à décrire le processus ayant permis d’évaluer la transparence sémantique des mots dérivés chez les locuteurs du français québécois. Pour rappel, un mot dérivé est formé à partir d’un radical auquel on ajoute un affixe, comme un préfixe ou un suffixe. La transparence sémantique fait référence à la facilité avec laquelle le sens d’un mot dérivé peut être déduit à partir de la signification de ses éléments constitutifs, notamment sa racine, son préfixe ou son suffixe. En d’autres termes, un mot est considéré comme sémantiquement transparent lorsque la relation entre sa structure morphologique et son sens est évidente pour les personnes locutrices. Ainsi, le sens du mot « redémarrer » est probablement plus facilement à deviner à partir de son préfixe -re et du radical -démarrer que le sens du mot « déjeuner », dont la combinaison du préfixe -dé et du radical -jeûner signifie « cesser de jeûner ».
L’étude s’est donc penchée sur la manière dont les locuteurs perçoivent cette transparence, en tenant compte de plusieurs facteurs : le type d’affixation utilisé dans la formation du mot dérivé, les caractéristiques des personnes, incluant leur niveau de connaissance du français (français comme langue maternelle ou seconde). Cette étude a permis d’enrichir l’analyse morphologique du français québécois parlé. L’évaluation de la transparence sémantique est essentielle, car la morphologie contribue de manière significative à la fluidité de lecture et à la compréhension des mots, notamment chez les personnes rencontrant des difficultés à décoder les mots.
Pour mener cette évaluation, une étude en ligne a été réalisée auprès de plus de 400 personnes participantes volontaires (voir la figure 2 ci-dessous présentant l’étude de la transparence sémantique).



{kind=link}