We are pleased to present an article detailing the recent updates to an ambitious project named SyllabO+.
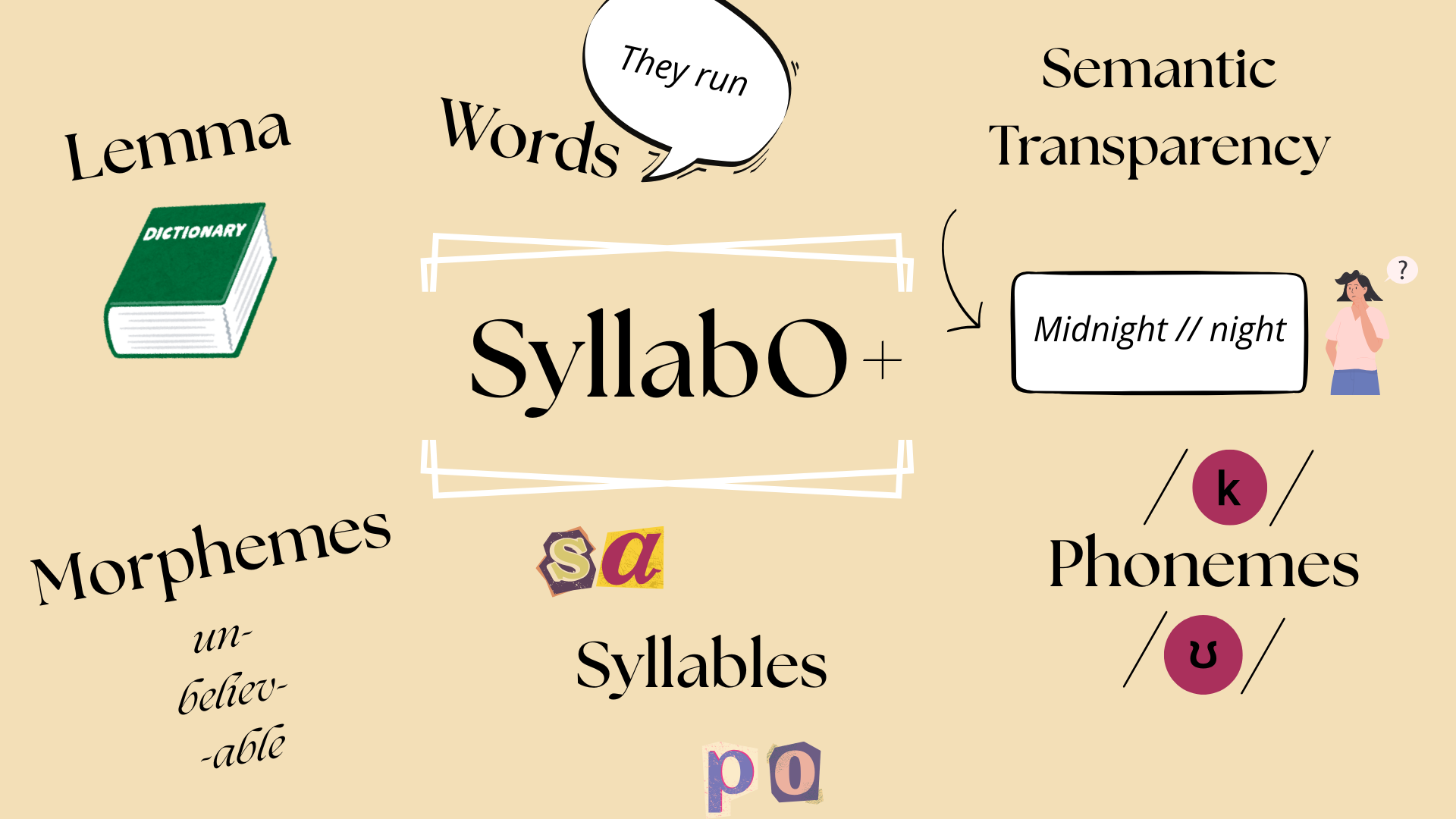
Started in the summer of 2013, the SyllabO+ project, developed by Pascale Tremblay and her team, particularly Pascale Bédard, then an undergraduate student in language sciences, aims to analyze Quebec French as it is spoken, taking into account speakers’ age, gender, and communication contexts. As part of the project, a large corpus of recordings from 184 Quebec French speakers, later expanded to 225, was compiled. Some participants were recorded in formal settings, others in informal ones. All recordings were transcribed using the International Phonetic Alphabet (IPA) by the team. The transcriptions were then segmented into words, syllables, and phonemes. Phonemes are the smallest sound units in a language that can differentiate meaning between words. For example, the words bath and path both contain the phonemes “a” and “th” (written /æ/ and /θ/ in IPA), but they differ in the phonemes /b/ and /p/.
In 2016, two databases were created: the phoneme and syllable databases, offering an inventory of the syllables and phonemes of spoken Quebec French. These databases allow for in-depth research on the structure and frequency of these language units. They provide information on how frequently certain phonemes and syllables occur, their transition probabilities (e.g., the likelihood that one syllable follows another), and the statistical relationships between them. Considering that few tools exist for the study of spoken Quebec French, SyllabO+ represents a valuable resource for research across multiple fields, including psycholinguistics, phonetics, speech-language pathology, and the cognitive neuroscience of language. One of its major strengths lies in its focus on spontaneous spoken language, offering an authentic snapshot of everyday language use.
SyllabO+ also stands out for its inclusion of a wide range of indicators from various linguistic domains—phonetics, phonology, lexicon, and morphology—all derived from the same group of speakers. This work was first published in the international journal Behavior Research Methods in 2017. To read the full article, click here. SyllabO+ is freely available online on our website (click here).
The article we present to you today is the second published as part of this project. It pursues three main objectives. First, it describes the expansion of the corpus of spoken Quebec French within the SyllabO+ project, as well as the creation, since 2017, of three new databases: words, lemmas, and morphemes. Second, it presents a study conducted to evaluate the semantic transparency of the words in the corpus. Finally, it explores the implications of these data for researchers in various fields, such as education, linguistics, and speech-language pathology.
The Update Process of the SyllabO+ Project and the Creation of the Unique Words, Lemmas, and Morphemes Databases
As part of the expansion of the SyllabO+ project, the original corpus was enlarged to enable the creation of three new databases: unique words, lemmas, and morphemes. This project was carried out by a team composed of Pascale Tremblay, Noémie Auclair-Ouellet, Pascale Bédard, Patrick Drouin, Alexandra Barbeau-Morrison, and, finally, Alexandra Lavoie, a lab assistant who segmented all the words in the corpus into morphemes. Details regarding the updates to the corpus are presented in Figure 1 below. These new databases are available on our website by clicking here.





{kind=link}